The financial services industry is undergoing a period of digital transformation, with banks actively looking for and implementing new technologies to gain advantages in the highly competitive financial services market. In this context, CompatibL recognized the opportunity to explore the practical applications of the latest hardware advancements from AMD for high-performance financial computing.
To assess the real-world impact of these innovations on financial risk management, we decided to leverage AMD technology to conduct calculations for a derivatives portfolio on CompatibL Platform.
CompatibL Platform for risk management is an award-winning solution for trading, market, and credit risk, regulatory capital, limits, and initial margin. It is trusted by its numerous long-standing clients and partners, which are primarily banks, asset managers, and hedge funds. CompatibL’s cloud-based risk management platform features a highly scalable cloud architecture, advanced real-time analytics, innovative risk models, and an AI module for model governance and document comprehension.
This case study highlights our findings as well as insights gained from testing CompatibL Platform on AMD hardware, with a focus on improving the speed of financial instruments’ calculations.
What was measured
The goal of this case study was to test the end-to-end batch calculation with fourth generation (4th Gen) AMD EPYC processors for a typical portfolio of trades.
Our hypothesis was that compute-intensive calculations, such as derivatives portfolio calculations, benefit from the all-physical cores supplied in the 4th Gen AMD EPYC CPUs, and the AVX-512 instructions first made available in this generation of EPYC processors perform well without any degradation in clock speed.
To do this, we used a portfolio of 20,213 over-the-counter (OTC) derivatives. The portfolio was structured as follows:
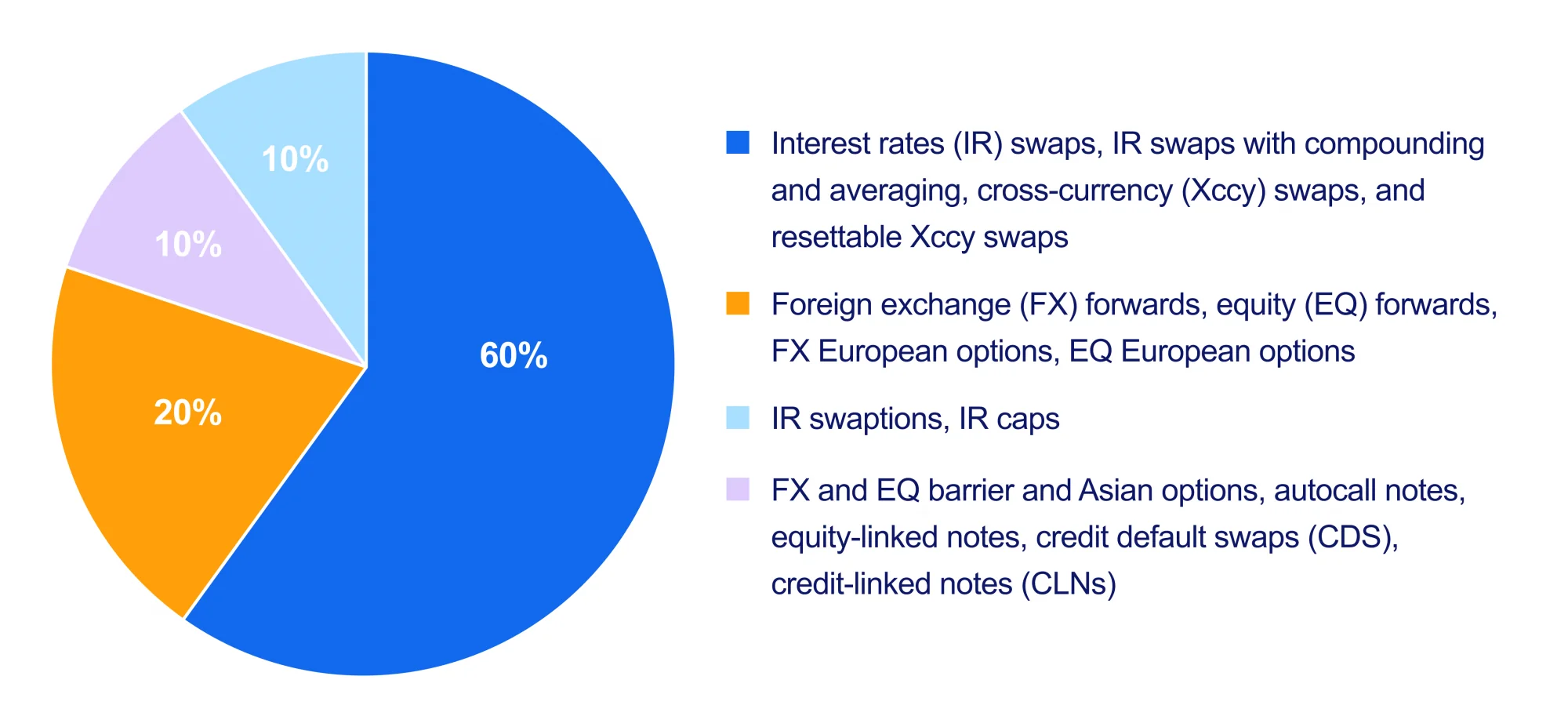
Diagram 1. The structure of the portfolio.
The software was configured to calculate the following analytics: PV, UCVA1, UCVA2, FVA1, FVA2, DVA1, DVA2, BCVA1, BCVA2.
The batch calculation also targeted sensitivities:
- FX delta
- EQ delta
- IR delta, parallel and bucketed
- FX vega, parallel and bucketed
- EQ vega, parallel and bucketed
- IR vega, parallel and bucketed
All calculations were carried out with a full breakdown to individual position level – i.e., for the sensitivity calculation, CompatibL reported both base and sensitivity values for the portfolio total, for each counterparty, and for each individual position. As the goal was to test performance for compute-intensive calculations, the bump-and-reprice method was used for sensitivity calculations rather than adjoint algorithmic differentiation (AAD).
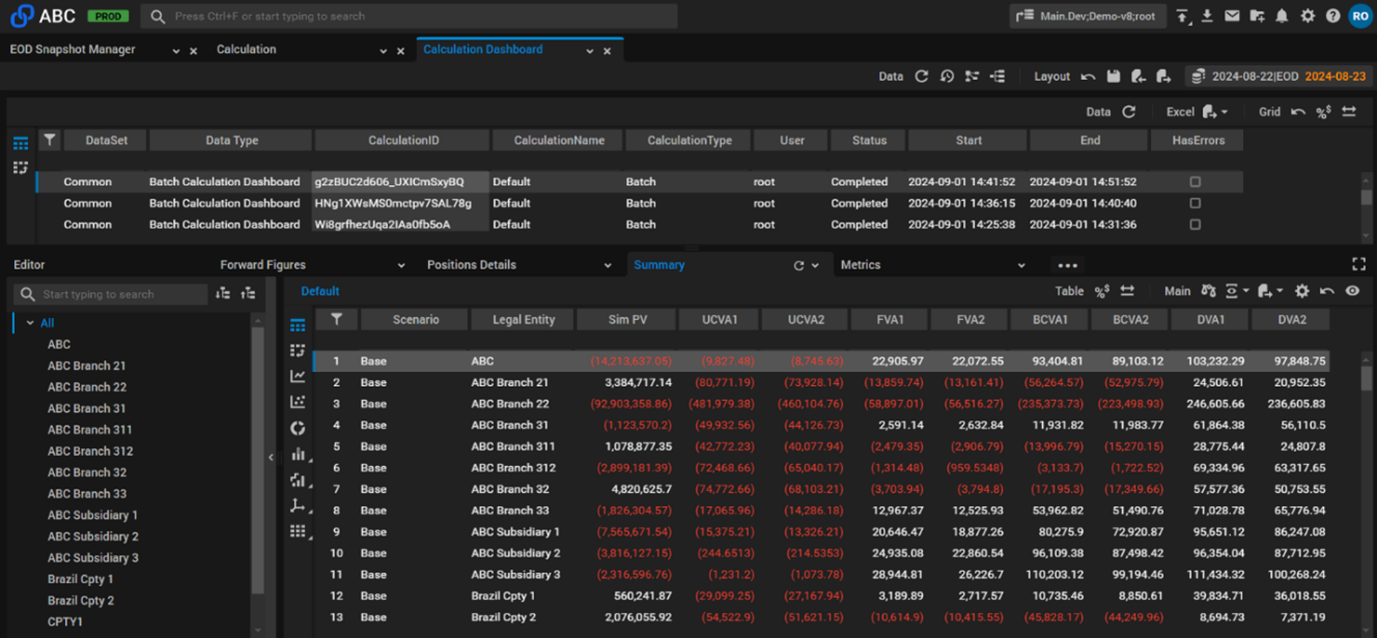
Screenshot 1. Portfolio-level XVA and breakdown by counterparty.
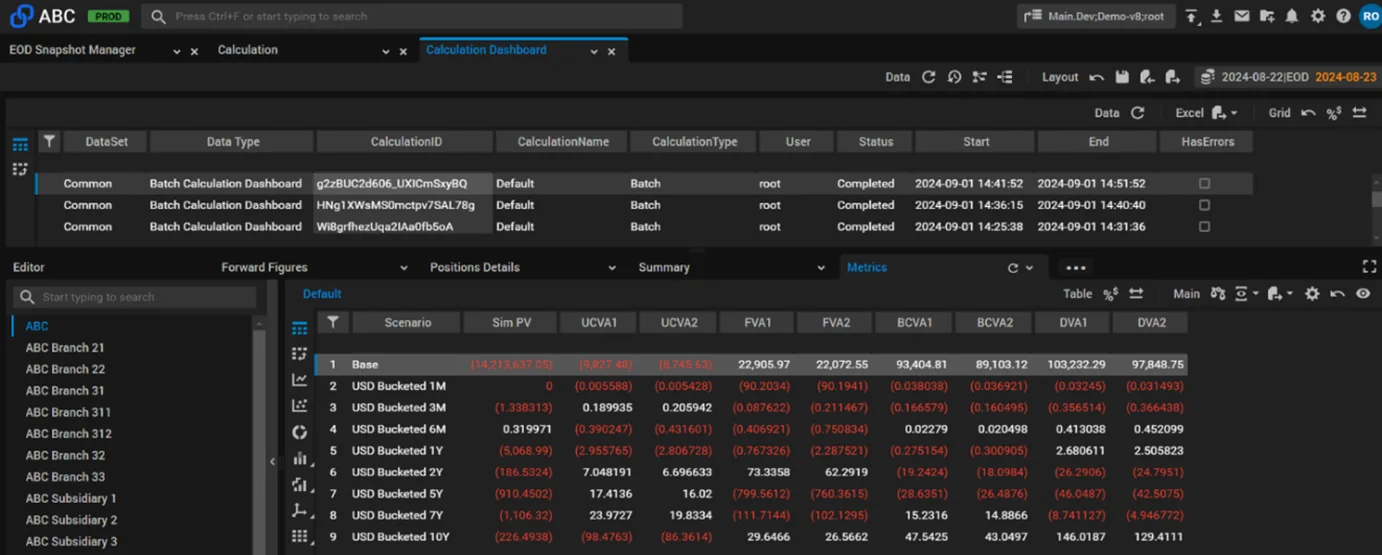
Screenshot 2. Counterparty-level zero rate sensitivities.
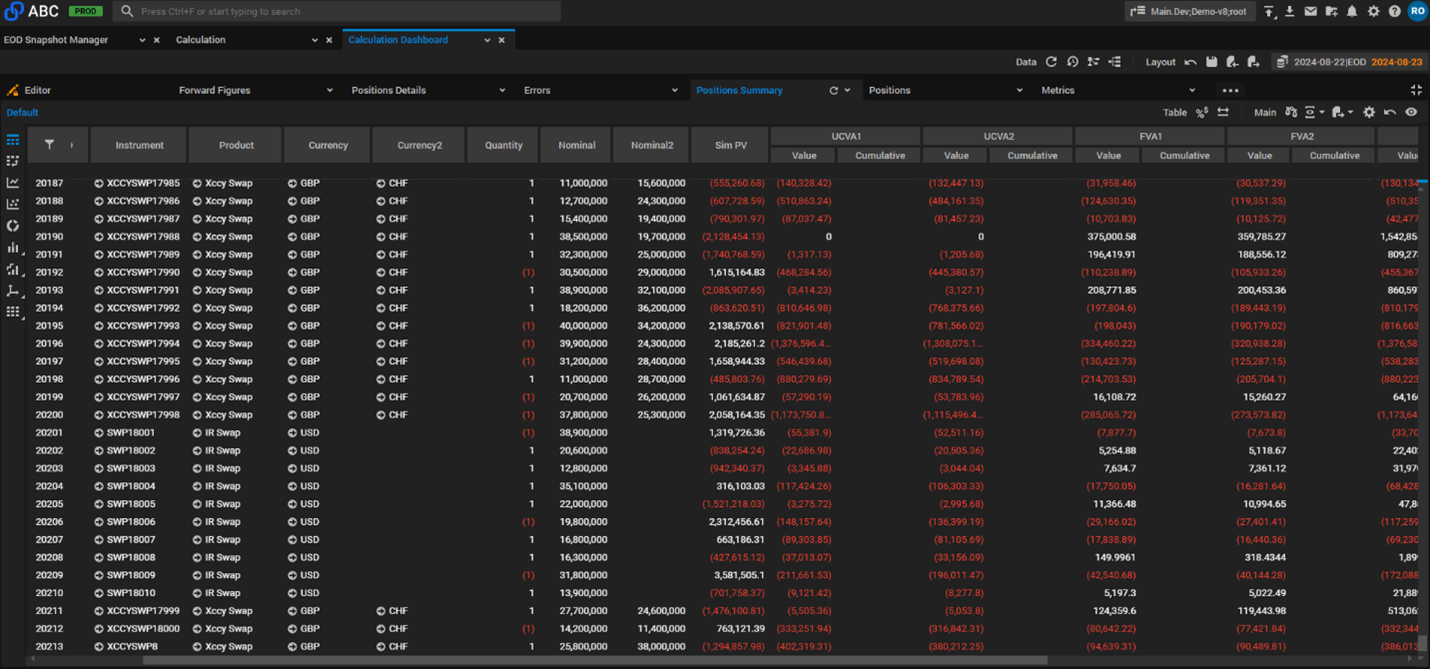
Screenshot 3. Position level breakdown.
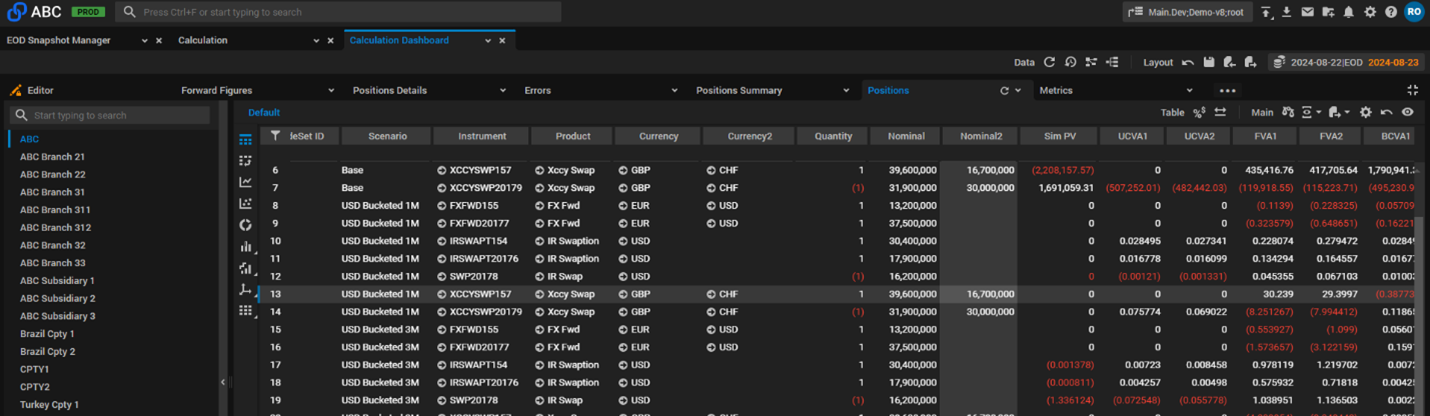
Screenshot 4. Position sensitivities.
Calculation environment
To assess the performance of AMD EPYC 4th Gen server processors, CompatibL’s risk analytics software was deployed in AWS with Kubernetes, snapping EC2 M7a instances in different configurations. The choice of M7a instances was driven by CompatibL Platform’s requirements to have 4 GiB of memory per core. While AMD announced their 5th Generation EPYC processors this past October during their Advancing AI event, the M7a instance and its counterparts (C7a, R7a, and Hpc7a) remain the most recent EPYC offerings in AWS as of time of writing. We expect AMD EPYC 5th Gen-based AWS instances to become available in the future, with improved performance based on the latest generational enhancements as detailed by AMD.
Amazon EC2 M7a instances, powered by 4th Gen AMD EPYC processors, promise to deliver better performance compared to M6a instances. In addition to supporting Double Data Rate 5 (DDR5) memory to enable high-speed access to data in memory and delivering 2.25 times more memory bandwidth, M7a instances also support Advanced Vector Extensions (AVX-512), Vector Neural Network Instructions (VNNI), and brain floating point (bfloat16), broadening workload coverage.
One of the major differences between M7a instances and the previous generations of instances is their vCPU-to-physical processor core mapping. Every virtual central processing unit (vCPU) on an M7a instance is a physical CPU core. This means there is no simultaneous multithreading (SMT). By contrast, every vCPU on prior generations (such as M6a instances) is mapped to a single thread of a CPU core.
M7a instances are ideal for applications that benefit from high performance and high throughput, such as financial risk management calculation and quant applications.
Results
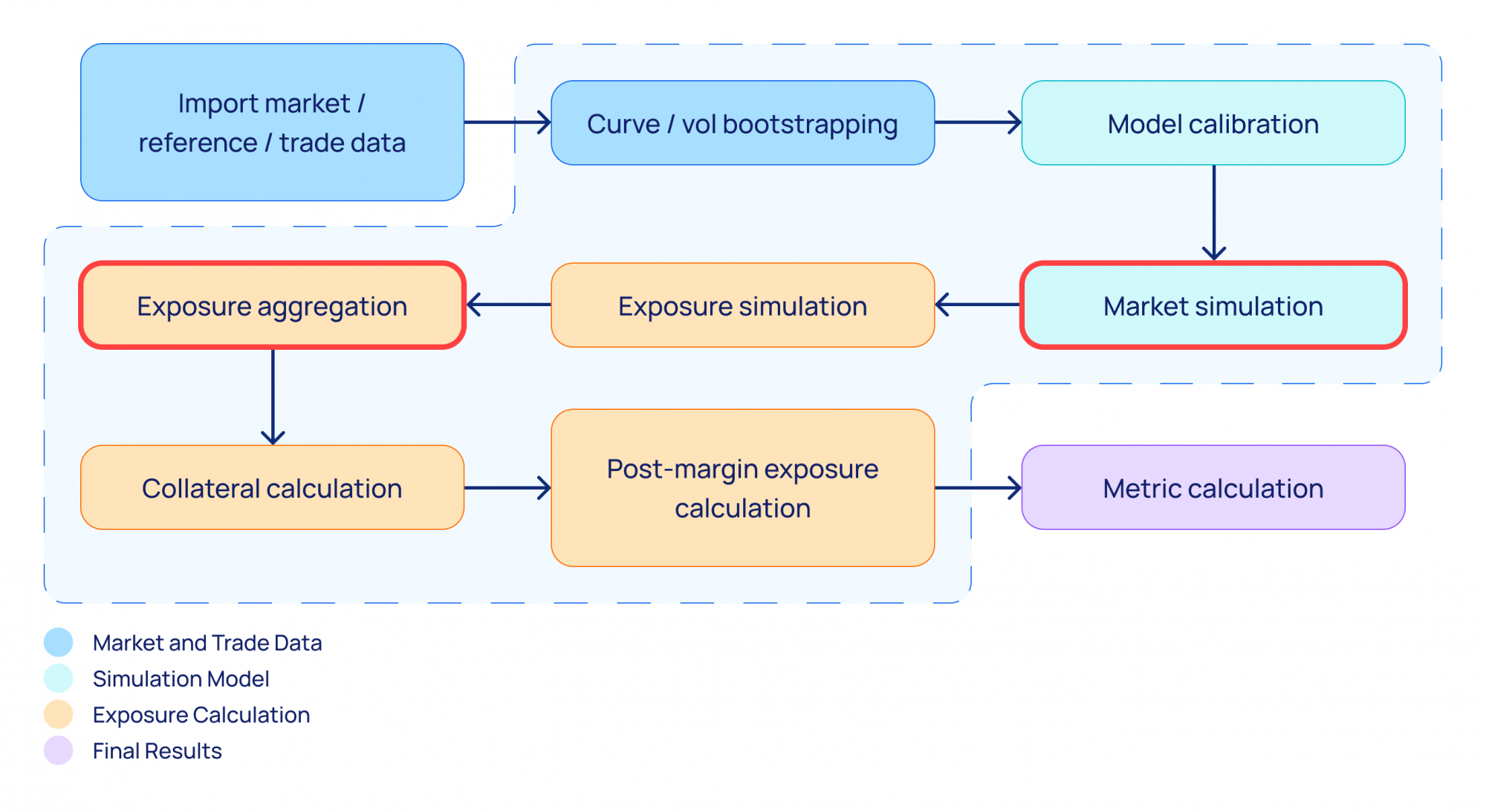
The analytics calculated as part of the end-to-end batch in this case study required simulation of possible future market states and trade repricing on these future dates. The calculation workflow is better explained by the following diagram:
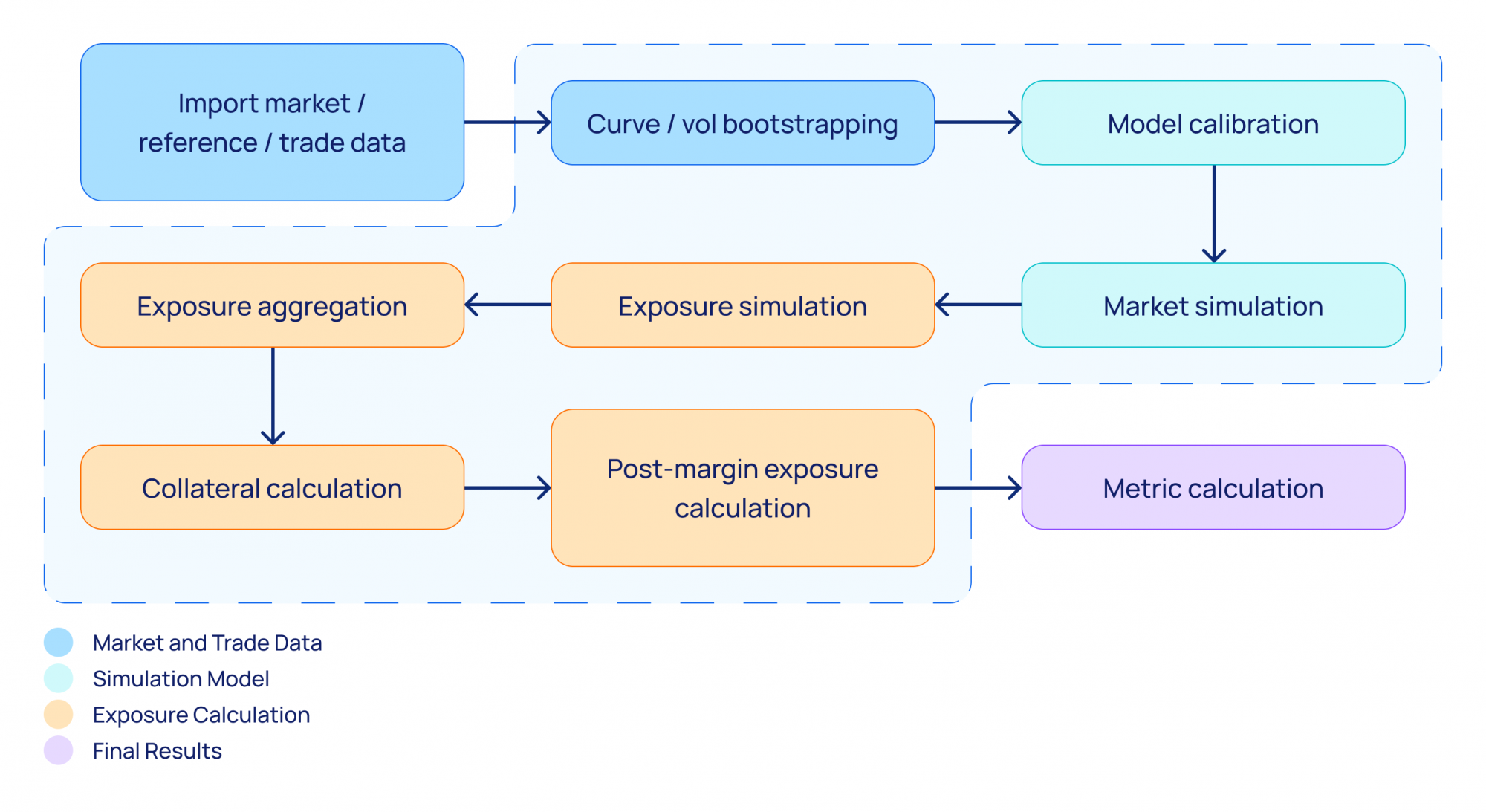
Diagram 2. Calculation workflow.
Once trade data and market data are imported into the system, the model is calibrated to define volatilities for the stochastic simulation process. The market simulation generates a distribution of states for each future date from the set of modeling dates. Then, for each future date, the trade value is calculated; this step, called exposure simulation, is where the market state trade value is calculated for each trade and each future date. Based on the underlying instrument, either a closed-form solution or American Monte Carlo simulation is used.
Once all individual trade exposures are generated, they are aggregated using netting rules (exposure aggregation), after which Credit Support Annex (CSA) is applied (collateral calculation and post-margin exposure calculation). Given the stochastic nature of the calculations, all these steps operate on matrices: individual trade exposure is nothing but a two-dimensional matrix, where the rows are future dates and the columns are simulation paths.
For such heavy matrix-oriented calculations, the use of Advanced Vector Extensions (AVX) is paramount. As EC2 M7a supports AVX-512 extensions, this instance type benefits from built-in acceleration for demanding workloads that involve heavy vector-based processing. AVX instructions operate on multiple pieces of data at the same time, which is faster than operating on a single piece of data at a time. AVX-512 can accelerate data center performance for a variety of workloads, including scientific simulations, financial analytics, and artificial intelligence/deep learning applications.
To test AVX performance, we compared non-vectorized code, which calculates the potential future exposure (PFE) of a cross-currency swap using American Monte Carlo (AMC), with its vectorized counterpart. This calculation operates on a two-dimensional (2D) matrix, where one dimension is the simulation paths, and the other dimension is the set of future dates. We ran the tests on different path counts, as quantile measures like PFE 95% or PFE 99% often require greater precision. We observed the following results:
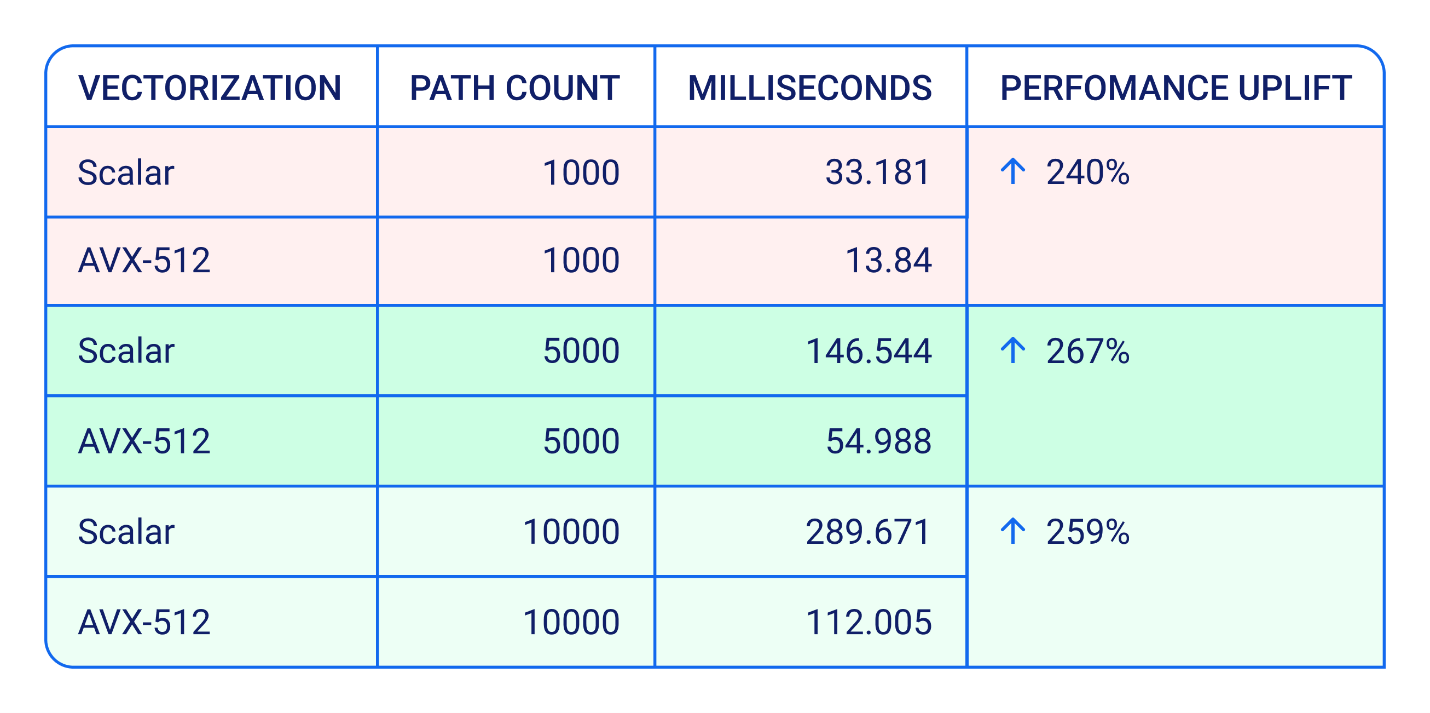
Table 1. Non-vectorized vs. vectorized code, results.
AMD AVX-512 gives us roughly two times better performance using CompatibL analytics. This ratio stays constant as the path count is increased. We obtain very similar results when we test individual asset classes (e.g., IR swaps or Barrier EQ options), and we do not observe any drop in CPU clock speed or degradation of CPU instructions per second (iops). Throughout all our tests, the average clock speed was 3.35 GHz, and the iops averaged 1.81, sometimes peaking at 3.
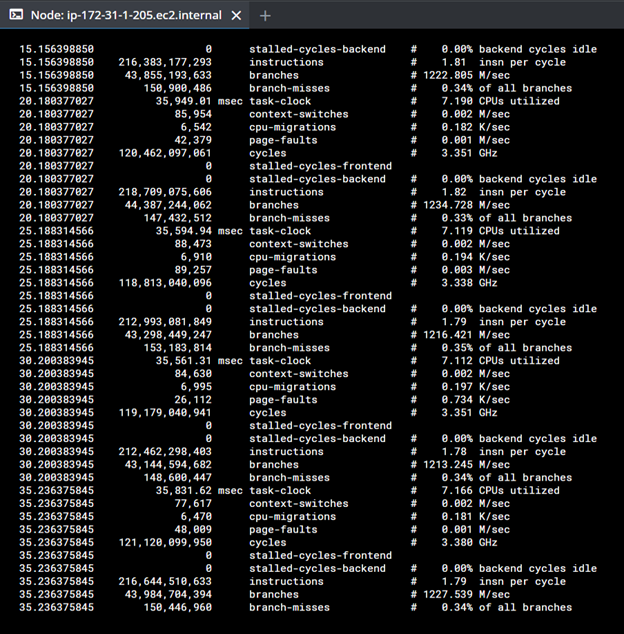
Screenshot 5. Performance profile on a single VM.
The next test was to check CPU saturation in a manycore configuration. CompatibL has significant experience with non-uniform memory access (NUMA) architectures, and in the past, we have observed practical cases where hardware providers with 64-core (or more) processors did not perform well enough due to locks on the memory bus. On an 8-core machine, we allocate 7.5 cores to the CompatibL process (Kubernetes pod), as the remaining 0.5 cores are used by Kubernetes itself. On a 48-core machine, we allocate 7.5 cores per CompatibL process and start six processes so that, again, we utilize almost all available cores. As expected, the run on a 48-core machine is faster than the one on the 8-core machine, so we normalize the results on single-core performance; i.e., we divide the total run time by the total number of cores used for the calculation. The table below shows an almost linear single-core benchmark performance regardless of the specifications of actual AMD family machines.
For both these tests, the monitoring shows full CPU saturation for all the cores available on the machine.
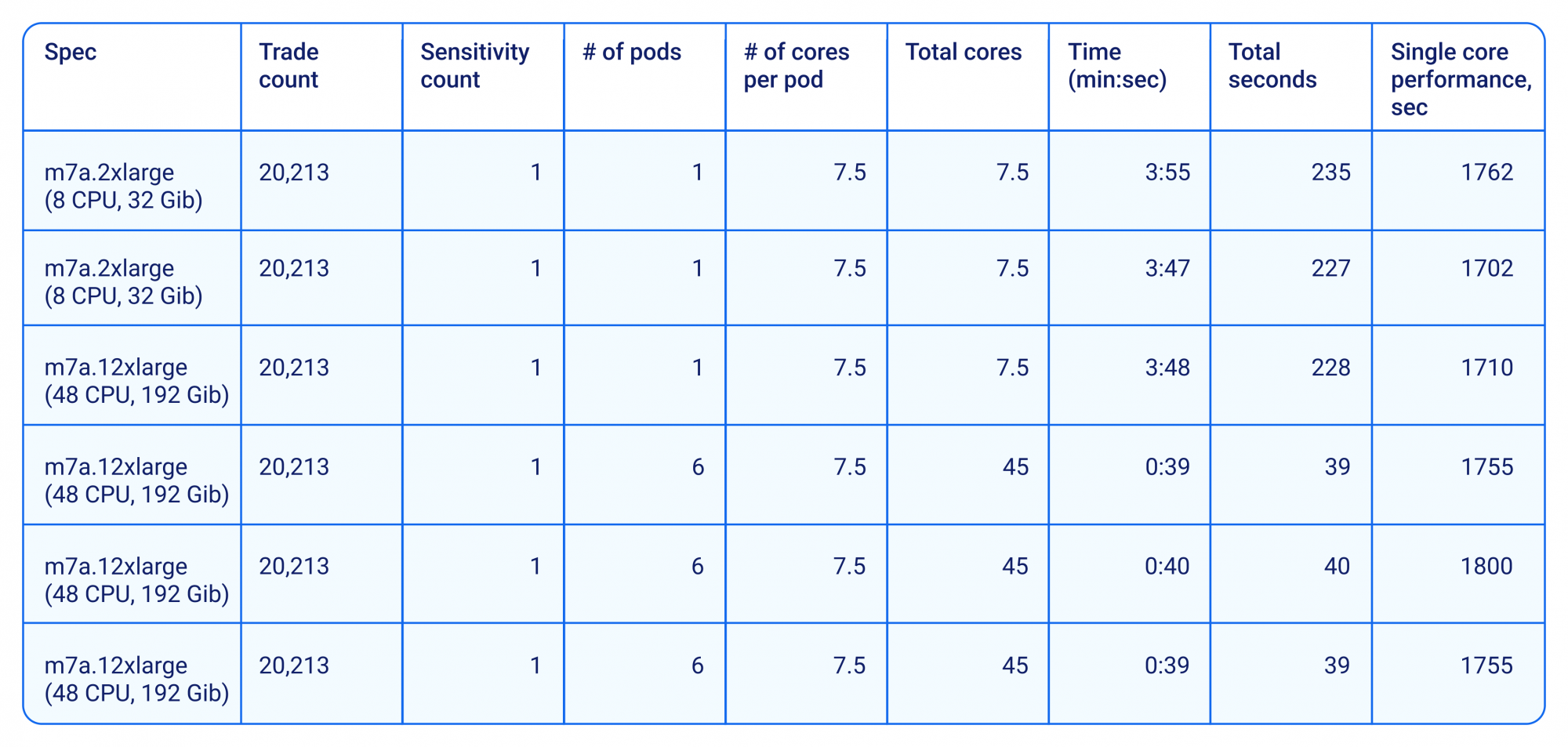
Table 2. Run statistics on a single VM.
One very interesting aspect for us was the behavior of AMD CPUs in a cloud configuration. We ran another set of tests and gradually increased the number of vCPUs and number of nodes used for the calculation. As one may expect, the increase in CPUs should linearly improve the total run time. For a perfectly balanced system with no extra overhead or idle times, the ratio should be 2 (i.e., twice as many CPUs lead to two-times better performance, which is the same as keeping the single-core time constant. Our findings confirmed this observation for AMD CPUs. To normalize the results in terms of single-core performance, we again divide total run time by the total number of cores used for the given test. To scale CompatibL Platform horizontally, we also change the number of cores per process (Kubernetes pod), and we use a node pool with automated scaling so that hardware is added and removed dynamically. For large manycore clusters, we add more load by adding sensitivity runs. Sensitivity is a portfolio valuation when some market factors are shifted. We start with one sensitivity, representing the base context (market data is not shifted), and gradually go up to 24 sensitivities: interest rate, FX, or equity scenarios.
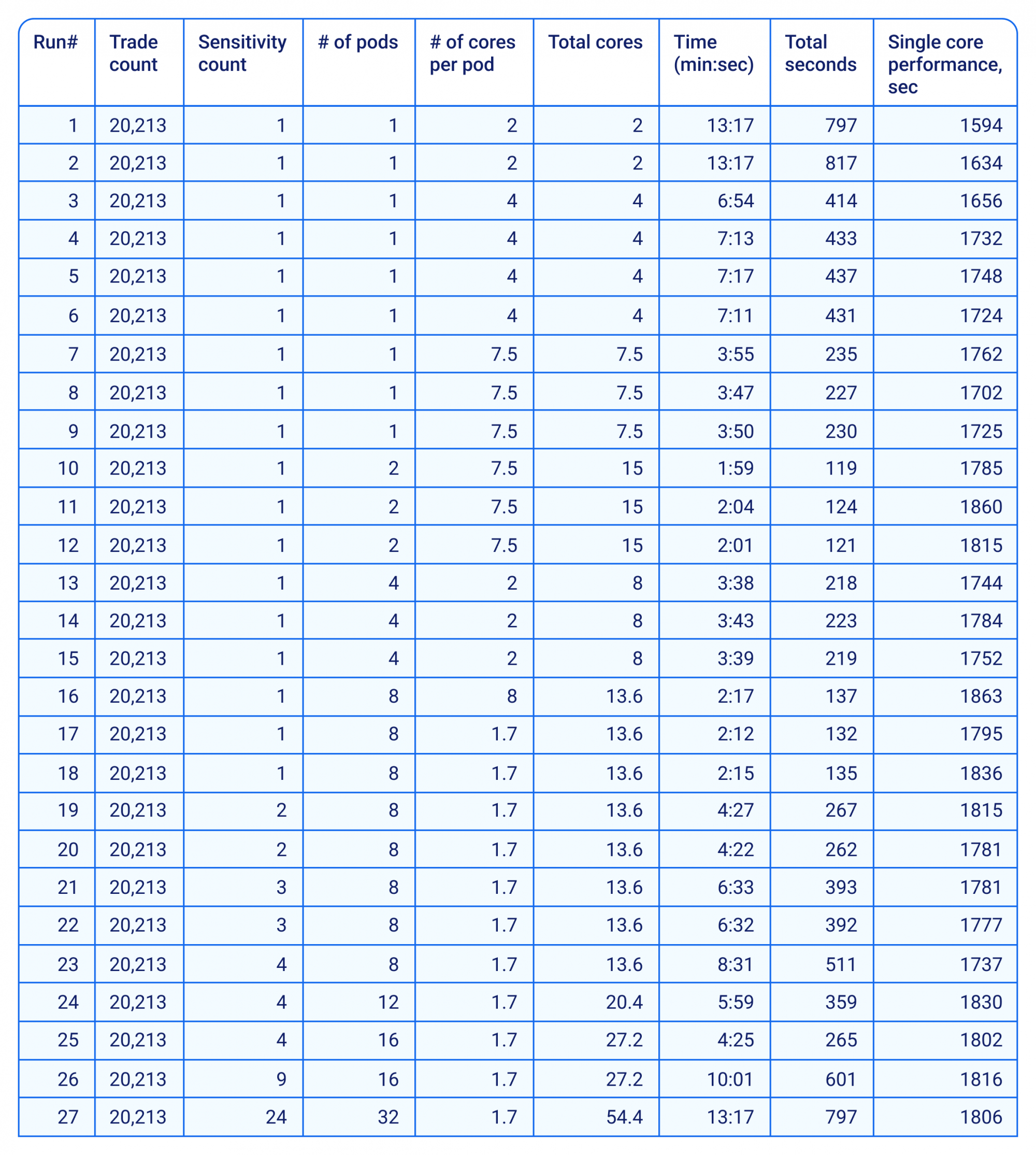
Table 3. Run statistics on a compute cluster.
When we plot the single core equivalent across all the runs, we can see a nearly straight horizontal line. There is a slight tendency for performance to drop by a few percent when the number of CPUs grows, which is expected given the nature of calculations CompatibL is running. Specifically, with reference to Diagram 2 in the results section above showing the calculation workflow, the market simulation step is not carried out in parallel, and there are also synchronization checkpoints before each of the calculation steps when some workers are idle (e.g., exposure aggregation cannot be started before all the individual trade exposures are calculated):
With SMT (and hyperthreading) two independent instructions streams are fed into a single core. These instruction streams share the core’s physical resources, the most important of which are the caches and the execution units (e.g. FPU). SMT can offer an advantage provided there are enough resources, with the one stream taking up dispatch and execution slots that the other stream is unable to fill. But if both instruction streams have relatively large working set sizes, the streams evict each other’s data from cache and the results can be worse. Disabling SMT dedicates all the c
ore’s resources to a single instruction stream and is a good tradeoff when portfolio structures, analytics, and quality settings may change in the future or are not yet finalized.
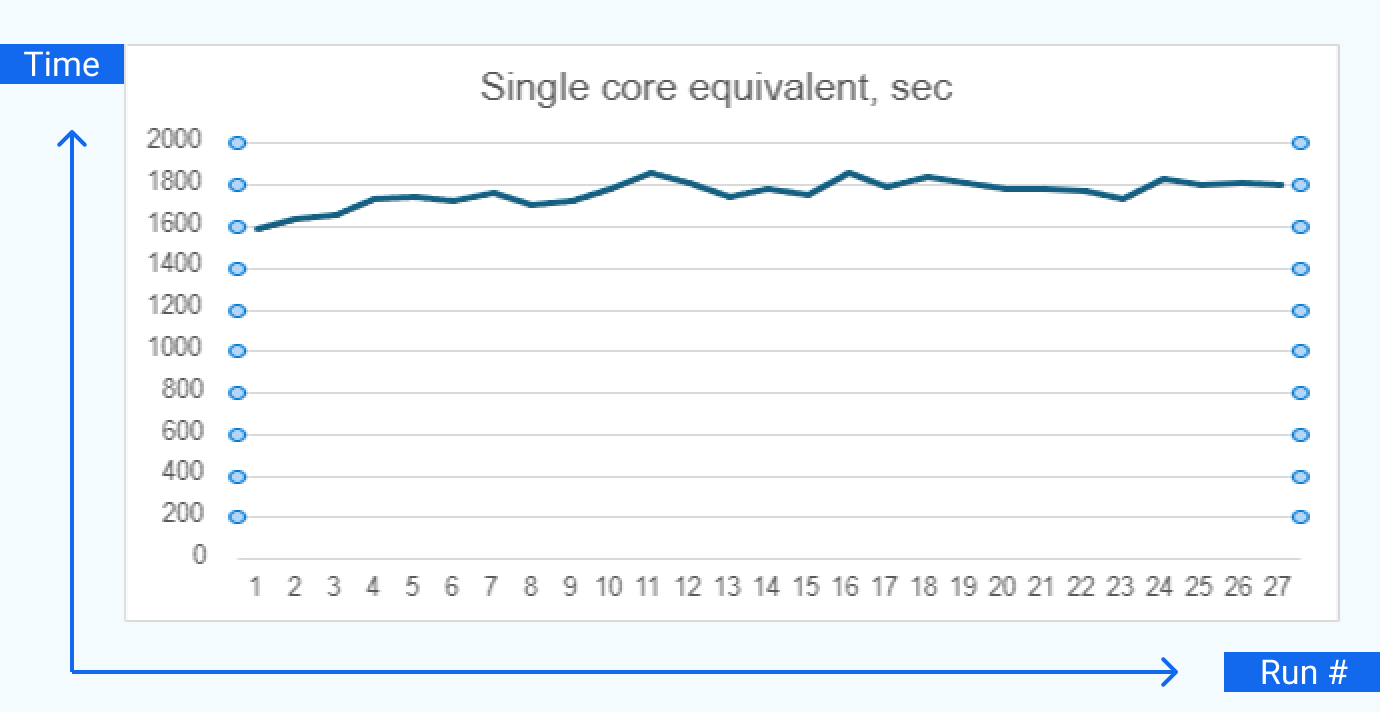
Graph 1. Single core equivalent time.
The CPU usage was constantly monitored, and we confirmed true core allocation to the pods running the load. Below we show the charts obtained from AWS.
CPU usage: roughly 25%, 2 out of 8 cores.
Screenshot 6. AWS VM usage for 2 out of 8 cores.
CPU usage: 50%, 4 out of 8 cores.
Screenshot 7. AWS VM usage for 4 out of 8 cores.
Summary of key observations
- The AVX-512 instruction set in 4th Gen EPYC processors enables exposure calculation on CompatibL library to double in speed.
- Calculations as run on CompatibL Platform scale linearly, with a constant single-core equivalent time across all CPU sizes (2, 4, 8, …, 48 CPUs), which confirms the benefit of the no-SMT all-cores-physical mode provided by AMD in its AWS M7a instances.
- 4th Gen AMD EPYC CPUs work perfectly well for cloud-native workflows, including in testing, for which CompatibL adopted an AWS EKS cluster of 15 nodes.
- Across all calculation modes (vectorized/scalar), with a small (8-core)/large (48-core) CPU, a single processor, or a many-node cluster, the 4th Gen AMD EPYC processors showed an average 3.35 GHz clock speed and 1.81 iops, with peak values reaching 3 iops.
Applications of this case study
CompatibL Platform on Amazon EC2 M7a instances provides a robust solution for financial risk management, handling complex quant calculations, large portfolios, AI and deep learning, and more.
With its impressive performance and scalability, CompatibL Platform for risk management and its financial derivatives analytics suite can significantly improve your financial organization’s efficiency and enable you to consolidate workloads using fewer instances.
Kumaran Siva, Corporate Vice President, Strategic Business Development, AMD, says:
“As financial services embrace digital transformation, the 4th Gen AMD EPYC processors are designed to meet the demands of intensive calculations in cloud-native environments. CompatibL’s results showcase how our processors’ support for AVX-512 and all-physical core mode can accelerate financial analytics, helping firms optimize workloads and improve efficiency in real-time risk calculations.”
Contact us at info@compatibl.com to book a free consultation.


